








How To Restore Deepseek
페이지 정보
Joesph 작성일25-02-17 12:36본문
Free DeepSeek coder - Can it code in React? Released under Apache 2.Zero license, it may be deployed domestically or on cloud platforms, and its chat-tuned model competes with 13B fashions. In addition, we carry out language-modeling-based evaluation for Pile-take a look at and use Bits-Per-Byte (BPB) because the metric to ensure fair comparison among models using different tokenizers. As well as, in contrast with DeepSeek-V2, the brand new pretokenizer introduces tokens that mix punctuations and line breaks. At the small scale, we train a baseline MoE model comprising 15.7B complete parameters on 1.33T tokens. For the MoE half, we use 32-method Expert Parallelism (EP32), which ensures that each expert processes a sufficiently massive batch measurement, thereby enhancing computational efficiency. Compared with DeepSeek-V2, we optimize the pre-coaching corpus by enhancing the ratio of mathematical and programming samples, whereas expanding multilingual protection past English and Chinese. While inference-time explainability in language fashions remains to be in its infancy and will require significant improvement to reach maturity, the child steps we see right now could help result in future techniques that safely and reliably assist people. To scale back reminiscence operations, we advocate future chips to enable direct transposed reads of matrices from shared reminiscence before MMA operation, for those precisions required in each training and inference.
 However, on the H800 architecture, it is typical for two WGMMA to persist concurrently: whereas one warpgroup performs the promotion operation, the opposite is ready to execute the MMA operation. So as to handle this difficulty, we adopt the strategy of promotion to CUDA Cores for higher precision (Thakkar et al., 2023). The method is illustrated in Figure 7 (b). As talked about before, our high quality-grained quantization applies per-group scaling elements along the interior dimension K. These scaling elements could be efficiently multiplied on the CUDA Cores because the dequantization process with minimal further computational value. POSTSUBSCRIPT is reached, these partial results will probably be copied to FP32 registers on CUDA Cores, where full-precision FP32 accumulation is carried out. To be particular, throughout MMA (Matrix Multiply-Accumulate) execution on Tensor Cores, intermediate outcomes are accumulated using the limited bit width. For example, the Space run by AP123 says it runs Janus Pro 7b, but instead runs Janus Pro 1.5b-which may find yourself making you lose quite a lot of free Deep seek time testing the mannequin and getting bad results. Note that as a result of modifications in our evaluation framework over the previous months, the performance of DeepSeek-V2-Base exhibits a slight difference from our beforehand reported outcomes.
However, on the H800 architecture, it is typical for two WGMMA to persist concurrently: whereas one warpgroup performs the promotion operation, the opposite is ready to execute the MMA operation. So as to handle this difficulty, we adopt the strategy of promotion to CUDA Cores for higher precision (Thakkar et al., 2023). The method is illustrated in Figure 7 (b). As talked about before, our high quality-grained quantization applies per-group scaling elements along the interior dimension K. These scaling elements could be efficiently multiplied on the CUDA Cores because the dequantization process with minimal further computational value. POSTSUBSCRIPT is reached, these partial results will probably be copied to FP32 registers on CUDA Cores, where full-precision FP32 accumulation is carried out. To be particular, throughout MMA (Matrix Multiply-Accumulate) execution on Tensor Cores, intermediate outcomes are accumulated using the limited bit width. For example, the Space run by AP123 says it runs Janus Pro 7b, but instead runs Janus Pro 1.5b-which may find yourself making you lose quite a lot of free Deep seek time testing the mannequin and getting bad results. Note that as a result of modifications in our evaluation framework over the previous months, the performance of DeepSeek-V2-Base exhibits a slight difference from our beforehand reported outcomes.
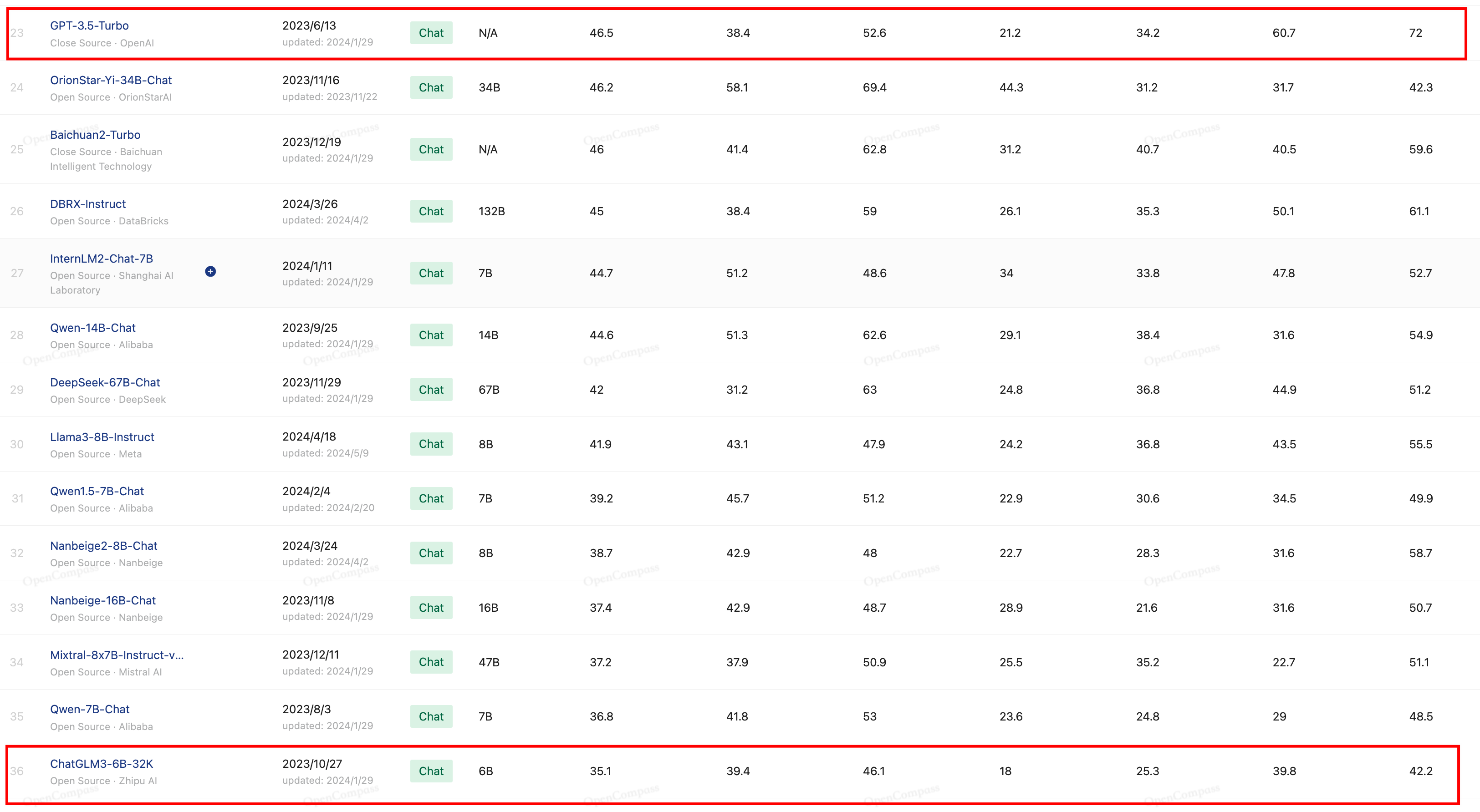 We built a computational infr Voice Control, permitting you to create new voices by shifting ten sliders for things like ‘gender,’ ‘assertiveness’ and ‘smoothness.’ Seems like a terrific thought, especially on the margin if we are able to decompose present voices into their elements. Alternatively, a near-memory computing method could be adopted, the place compute logic is positioned near the HBM. With an honest internet connection, any laptop can generate code at the identical fee using remote fashions. It’s widespread in the present day for companies to upload their base language models to open-source platforms. Even so, the kind of solutions they generate appears to depend on the level of censorship and the language of the immediate. This structure is applied on the document stage as a part of the pre-packing process.
We built a computational infr Voice Control, permitting you to create new voices by shifting ten sliders for things like ‘gender,’ ‘assertiveness’ and ‘smoothness.’ Seems like a terrific thought, especially on the margin if we are able to decompose present voices into their elements. Alternatively, a near-memory computing method could be adopted, the place compute logic is positioned near the HBM. With an honest internet connection, any laptop can generate code at the identical fee using remote fashions. It’s widespread in the present day for companies to upload their base language models to open-source platforms. Even so, the kind of solutions they generate appears to depend on the level of censorship and the language of the immediate. This structure is applied on the document stage as a part of the pre-packing process.
If you have any kind of inquiries with regards to wherever in addition to the way to utilize DeepSeek Chat, you can e-mail us in our page.
댓글목록
등록된 댓글이 없습니다.






